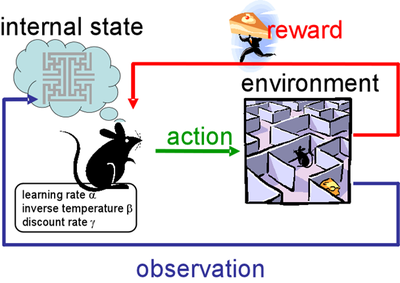
강화학습은 기본적으로,
쥐(Actor 혹은 Agent)가 action을 취하면 그에 따른 reward를 받고,
변화된 state를 관찰하여 다시 action을 취하는 방식이다.
Q 함수에 state와 action을 주면, 그에 따른 reward를 리턴한다고 생각하자.
(그러한 Q 형님이 있다고 가정하자.)
Agent가 알고 싶은 것은 최대 reward를 만드는 action이다.
이 내용을 다음 두 수학적 표기로 나타낼 수 있다.
max(a') Q(s, a') : s 라는 state에 a'을 바꾸어 줌으로써 얻을 수 있는 최대 reward값 (Q값)
argmax(a') Q(s, a'): (위와 이어지는 상황에서) 최대 Q값을 갖게하는 argument a'
Reference: Sung Kim 모두를 위한 RL강좌 정리
작성일: 2018. 10. 3.
'머신러닝, 딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| DQN (0) | 2022.03.12 |
|---|---|
| 강화학습 복습 자료 5: Stochastic World (0) | 2022.03.12 |
| 강화학습 복습 자료 4: Discounted future reward (0) | 2022.03.12 |
| 강화학습 복습 자료 3: Exploit & Exploration (0) | 2022.03.12 |
| 강화학습 복습 자료 2: Dummy Q-learning algorithm (0) | 2022.03.12 |


댓글